记录惊天巨坑enable ipv6 and dual stack for our product,从k8s安装开始
0. 原来产品是本地安装测试的,仅支持ipv4安装很简便,但这次要求支持ipv6/dualStack,根据官网文档,我们需要1.16版本以上的kubernetes,kubectl version查看本地版本:
1 | Client Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.8", GitCommit:"211047e9a1922595eaa3a1127ed365e9299a6c23", GitTreeState:"clean", BuildDate:"2019-10-15T12:11:03Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"windows/amd64"} |
1.14。。赶紧查docker desktop自带的kubernetes怎么更新,发现要写deploy测试或者重装k8s? 感觉不适用。因为这是docker自带的不知道重装会不会有别的影响。决定直接装到我们组的remote server上,这样测试也可以一步到位。
- 登上remote server发现第二个坑,机子连不了外网。。。连yum install都必须自己配置本地yum repo…一开始是想自己再装一个能连外网的虚拟机,把docker和k8s下载下来打好包再transfer到remote server上。
- setup redhat7 to local vm:
error when setup vm:VT-x is not available (VERR_VMX_NO_VMX)
solution: https://blog.csdn.net/imilano/article/details/83038682 (note: this action will affect the auto-start of docker) - enable the subscription before downloading docker:
https://blog.csdn.net/yl_1314/article/details/52044022
- 不太行,改用这个: https://github.com/wxdlong/ok8s
把包下到本地再放到60上
before downloading, need change user permission level on docker. run command with:
1
export MSYS_NO_PATHCONV=1
then add local user to group “docker-users”, “Hyper-V Administrators”,” Remote Desktop Users”,”Remote Management Users”
1
2
3PS H:\> net localgroup docker-users ERICSSON\<eid> /add
System error 1378 has occurred.
The specified account name is already a member of the group.1
2PS H:\> net localgroup "Hyper-V Administrators" ERICSSON\<eid> /add
The command completed successfully.1
2
3PS H:\> net localgroup "Remote Desktop Users" ERICSSON\<eid> /add
System error 1378 has occurred.
The specified account name is already a member of the group.1
2PS H:\> net localgroup "Remote Management Users" ERICSSON\<eid> /add
The command completed successfully.check shared docker in DockerDesktop
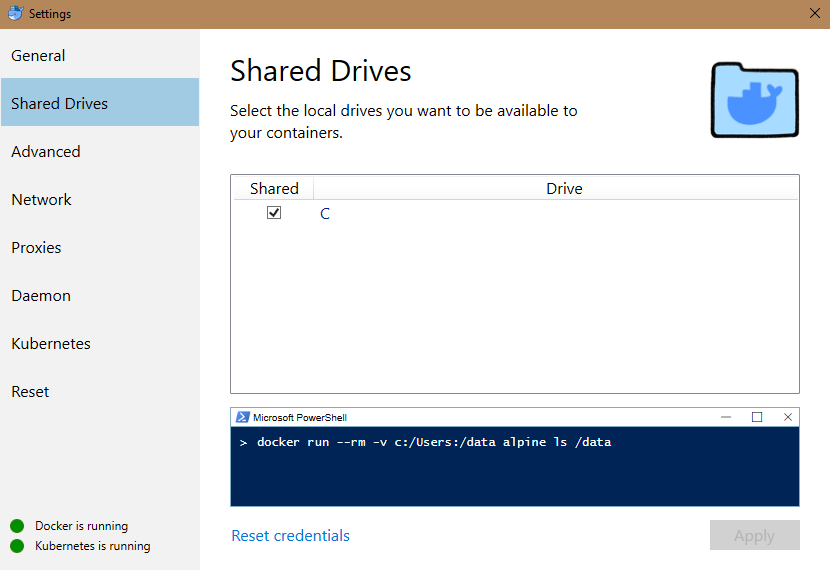
If still can’t see the volume, relogon PC, sec, and reset credentials.download packages to local folder
download1
$ docker run --rm -v '//c//Users//<eid>//download:/ok8s' registry.cn-hangzhou.aliyuncs.com/wxdlong/ok8s:v1.16.3
接下来就是把这个folder copy到host server上按教程往下走。
- 配置k8s和docker过程中遇到的错误
kubectl cluster-inforeturn
[error]The connection to the server localhost:8080 was refused - did you specify the right host or port?- https://blog.csdn.net/wzygis/article/details/91354870
1
2echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
- https://blog.csdn.net/wzygis/article/details/91354870
包里缺少flannel插件,自行安装
Copy
/etc/kubernetes/admin.confto$HOME/.kube/(on windows, on host server we just use/root):1
2
3
4
5[root@192-168-1-61 ~]# mkdir -p /root/.kube
[root@192-168-1-61 .kube]# cp -i /etc/kubernetes/admin.conf /root/.kube/config
[root@192-168-1-61 .kube]# ls -ltr /root/.kube/
total 8
-rw-------. 1 root root 5448 Mar 17 21:33 config这一步可能是多余的,因为上面第一个错误已经export过路径了
check pod status
1
2
3
4
5
6
7
8
9
10[root@192-168-1-61 ok8s]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-5644d7b6d9-5sp86 0/1 Pending 0 15h
kube-system coredns-5644d7b6d9-qjfz9 0/1 Pending 0 15h
kube-system etcd-192-168-1-61.maas 1/1 Running 0 15h
kube-system kube-apiserver-192-168-1-61.maas 1/1 Running 0 15h
kube-system kube-controller-manager-192-168-1-61.maas 1/1 Running 0 15h
kube-system kube-flannel-ds-amd64-vx4bw 1/1 Running 0 15h
kube-system kube-proxy-h4gdc 1/1 Running 0 15h
kube-system kube-scheduler-192-168-1-61.maas 1/1 Running 0 15hAccording to above result, the core DNS service is not started successfully.
flannel still not work, check
tail -f /var/log/messagesfoundUnable to update cni config: no valid networks found in /etc/cni/net.d+[fork/exec /opt/ok8s/cni/flannel: permission denied fork/exec /opt/ok8s/cni/portmap: permission denied]
go to foldercd /opt/ok8s/cni/and runchmod +x *.
tip: 无权限文件一般是白字,像上面这样授予全部权限会变为绿色,chmod 777 会把文件变为灰底再次
kubectl get pods -A可以看到两个core-dns node已经跑起来了
安装dashboard
1
2
3[root@192-168-1-61 ok8s]# kubectl get pods -A
kubernetes-dashboard dashboard-metrics-scraper-76585494d8-qb5mw 1/1 Running 0 101m
kubernetes-dashboard kubernetes-dashboard-5996555fd8-88qz6 0/1 ImagePullBackOff 0 101m这里pull image失败了,看了下应该是因为host server不能连外网,dashboard没大用处,这步暂时跳过
更换network插件为calico
装完flannel发现它还没支持ipv6,我人傻了,只好重新安装calico,先存一下calico支持ipv6 | dual-stack的官方文档, 以及非常详细的中文安装教程kubeadm reset后更改pod-network-cidr,重新init cluster:1
[root@192-168-1-61 ok8s]# kubeadm init --v=7 --pod-network-cidr=192.168.0.0/16 --kubernetes-version=v1.16.3
Calico作为CNI插件安装。必须通过传递–network-plugin=cni参数将kubelet配置为使用CNI网络, 这里–pod-network-cidr=192.168.0.0就是是用来给 controller-manager 用作自动分配pod子网 (用作给每个node上的pod分配IP address)
follow this official doc
由于不能连外网导致image pull不下来,手动下载过去
1
kube-system calico-node-vcbmc 0/1 Init:ImagePullBackOff 0 9m12s
1
2
3
4
5
6
7
8
9
10[root@192-168-1-61 nodeagent~uds]# kubectl describe pods calico-node-vcbmc -n kube-system
Events:
Type Reason Age From Message
Normal Scheduled 9m44s default-scheduler Successfully assigned kube-system/calico-node-vcbmc to 192-168-1-61.maas
Warning Failed 9m3s kubelet, 192-168-1-61.maas Failed to pull image "calico/cni:v3.13.1": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io on 10.136.40.87:53: server misbehaving
Normal Pulling 7m37s (x4 over 9m44s) kubelet, 192-168-1-61.maas Pulling image "calico/cni:v3.13.1"
Warning Failed 7m22s (x3 over 9m29s) kubelet, 192-168-1-61.maas Failed to pull image "calico/cni:v3.13.1": rpc error: code = Unknown desc = Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning Failed 7m22s (x4 over 9m29s) kubelet, 192-168-1-61.maas Error: ErrImagePull
Warning Failed 7m9s (x6 over 9m28s) kubelet, 192-168-1-61.maas Error: ImagePullBackOff
Normal BackOff 4m36s (x16 over 9m28s) kubelet, 192-168-1-61.maas Back-off pulling image "calico/cni:v3.13.1"download
calico:v3.13.1via https://docs.projectcalico.org/release-notes/, transfer the tgz package to host server.[root@192-168-1-61 calico]# docker load --input /home/eshibij/calico-v3.13.1/release-v3.13.1/images/calico-node.tar–> load calico image, check:1
2
3[root@192-168-1-61 calico]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
calico/node v3.13.1 2e5029b93d4a 5 days ago 260MB把
pod2daemon-flexvol,calico-cni,calico-kube-controllers也一起load了[error] pod describe find
calico 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate.
–> 这个一般是有另一个它依赖的node还没起来,查看/var/log/messages
–>[failed to find plugin "calico" in path [/opt/ok8s/cni]
–> 原因是ok8s把加载的image里的默认文件挂载路径改成了/opt/ok8s/cni。可以直接在/opt/cni/bin(插件加载默认路径) 下找到calico和calico-ipam二进制文件copy到/opt/ok8s/cni下,也可以修改calico.yaml里的文件路径后重新apply -f1
2
3
4
5
6
7
8
9
10
11[root@192-168-1-61 cni]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-788d6b9876-dzlrz 1/1 Running 0 15h
kube-system calico-node-fttdx 1/1 Running 0 15h
kube-system coredns-5644d7b6d9-dl8ft 1/1 Running 0 15h
kube-system coredns-5644d7b6d9-dzrdv 1/1 Running 0 15h
kube-system etcd-192-168-1-61.maas 1/1 Running 0 15h
kube-system kube-apiserver-192-168-1-61.maas 1/1 Running 0 15h
kube-system kube-controller-manager-192-168-1-61.maas 1/1 Running 0 15h
kube-system kube-proxy-l54q7 1/1 Running 0 15h
kube-system kube-scheduler-192-168-1-61.maas 1/1 Running 0 15h
modify kubelet.service
add--feature-gates="IPv6DualStack=true"afterExecStart=/opt/ok8s/bin/kubeletin file/usr/lib/systemd/system/kubelet.servicehost server network config
add configs to
/etc/sysctl.d/98-ok8s.conf1
2
3
4net.ipv6.conf.all.disable_ipv6 = 0
net.ipv6.conf.default.disable_ipv6 = 0
net.ipv6.conf.lo.disable_ipv6 = 0
net.ipv6.conf.all.forwarding=1run
sysctl -pto make these configs work
enable ipv6 on host server, add setting to/etc/sysconfig/network1
NETWORKING_IPV6=yes
check
ifcfg-xxxunder /etc/sysconfig/networkscripts/:1
2IPV6INIT=yes
IPV6_AUTOCONF=yesgenerate kubeconfig file to parse configs
[error] k8s v1.16.3 cannot parse subnet with comma
https://github.com/kubernetes/kubeadm/issues/1828
update K8s to v1.17.4
packages/images updated:binary file: kubeadm, kubelet, kubectl, kube-proxy, kube-scheduler
docker image: controller-manager, proxy, scheduler, apiserver, etcd, coredns
Note: thecorednsofficial package has to be loaded asdocker import coredns_1.6.5_linux_amd64.tgz(reason see https://visionary-s.github.io/%2F2020%2F01%2F20%2Fdocker%2F)
check package version after replace kubeadm file:kubeadm config images listreinstall following official docs
- [error] failed to execute operation file exists when
systemctl enable kubelet
solution :systemctl disable kubeletfirst, then redo enable action. ref - [error] cannot use “fe80::2a80:23ff:feb5:a150” as the bind address for the API Server
查到kubeconfig.conf中:原因:不能用scope为link的ipv6地址,要用scope为global的1
2
3
4
5
6
7apiVersion: kubeadm.k8s.io/v1beta1
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
##cgroup-driver: "systemd"
localAPIEndpoint:
advertiseAddress: fe80::2a80:23ff:feb5:a1502001:250:4000:2000::53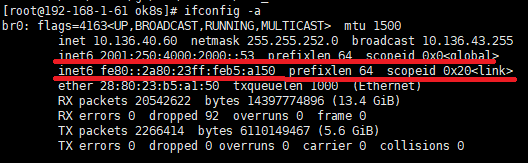
- etcd 3.4.3 官方镜像有点问题,导致etcd启动连接老是失败
solution: 把老版3.1的换了个tag。。。 - kube-controller-manager-192-168-1-61.maas CrashLoopBackOff
describe node, 发现在无限重启check docker logs;1
2Warning Unhealthy 91s kubelet, 192-168-1-61.maas Liveness probe failed: Get https://127.0.0.1:10257/healthz: dial tcp 127.0.0.1:10257: connect: connection refused
Warning BackOff 57s (x12 over 4m30s) kubelet, 192-168-1-61.maas Back-off restarting failed containersolution: ?1
2
3
4E0325 03:00:25.517141 1 core.go:91] Failed to start service controller: WARNING: no cloud provider provided, services of type LoadBalancer will fail
E0325 03:00:25.638913 1 core.go:232] failed to start cloud node lifecycle controller: no cloud provider provided
E0325 03:00:37.441597 1 controllermanager.go:521] Error starting "nodeipam"
F0325 03:00:37.441623 1 controllermanager.go:235] error starting controllers: New CIDR set failed; the node CIDR size is too big
- [error] failed to execute operation file exists when
install calico
error when starting calico node
1
kube-system calico-node-mzcnp 0/1 Init:CrashLoopBackOff 2 31s
descirbe event:
1
2
3
4
5Normal Scheduled 56s default-scheduler Successfully assigned kube-system/calico-node-mzcnp to 192-168-1-61.maas
Normal Pulled 12s (x4 over 56s) kubelet, 192-168-1-61.maas Container image "calico/cni:v3.13.1" already present on machine
Normal Created 12s (x4 over 56s) kubelet, 192-168-1-61.maas Created container upgrade-ipam
Warning Failed 12s (x4 over 56s) kubelet, 192-168-1-61.maas Error: failed to start container "upgrade-ipam": Error response from daemon: OCI runtime create failed: container_linux.go:346: starting container process caused "exec: \"/opt/ok8s/cni/calico-ipam\": stat /opt/ok8s/cni/calico-ipam: no such file or directory": unknown
Warning BackOff 8s (x4 over 41s) kubelet, 192-168-1-61.maas Back-off restarting failed containerbut I found the
calico-ipamis already under/opt/ok8s/cni/
原因:calico.yaml配置里路径写错了,按官网的来calico node起不起来
1
2
3
4
5
6
7
8
9
10
11[root@192-168-1-61 calico]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-788d6b9876-wkd5h 0/1 ContainerCreating 0 39m
kube-system calico-node-64q4h 0/1 Running 0 59s
kube-system coredns-6955765f44-k9cb5 0/1 ContainerCreating 0 45m
kube-system coredns-6955765f44-nznr9 0/1 ContainerCreating 0 45m
kube-system etcd-192-168-1-61.maas 1/1 Running 0 45m
kube-system kube-apiserver-192-168-1-61.maas 1/1 Running 0 45m
kube-system kube-controller-manager-192-168-1-61.maas 1/1 Running 0 45m
kube-system kube-proxy-ggjvb 1/1 Running 0 45m
kube-system kube-scheduler-192-168-1-61.maas 1/1 Running 0 45mdescribe calico-kube-controller:
1
2
3
4Warning FailedScheduling 59s (x30 over 39m) default-scheduler 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate.
Normal Scheduled 57s default-scheduler Successfully assigned kube-system/calico-kube-controllers-788d6b9876-wkd5h to 192-168-1-61.maas
Warning FailedCreatePodSandBox 54s kubelet, 192-168-1-61.maas Failed to create pod sandbox: rpc error: code = Unknown desc = [failed to set up sandbox container "27761f7a236bf9c092826ecb546dddad7c44a40fa1891faf6c45b14f330ad25d" network for pod "calico-kube-controllers-788d6b9876-wkd5h": networkPlugin cni failed to set up pod "calico-kube-controllers-788d6b9876-wkd5h_kube-system" network: error getting ClusterInformation: Get https://[10.24.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default: dial tcp 10.24.0.1:443: connect: connection refused, failed to clean up sandbox container "27761f7a236bf9c092826ecb546dddad7c44a40fa1891faf6c45b14f330ad25d" network for pod "calico-kube-controllers-788d6b9876-wkd5h": networkPlugin cni failed to teardown pod "calico-kube-controllers-788d6b9876-wkd5h_kube-system" network: error getting ClusterInformation: Get https://[10.24.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default: dial tcp 10.24.0.1:443: connect: connection refused]
Normal SandboxChanged 9s (x5 over 53s) kubelet, 192-168-1-61.maas Pod sandbox changed, it will be killed and re-created.原因:
https://[10.24.0.1]:443这个应该对应kubeconfig中kube-proxy下的clusterCIDR,应该跟kubelet下的podSubnet保持一致?(我用了serviceSubnet的网段)
还是不行,后面又改成了纯ipv6环境,配置文件kubeconfig.yml如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43apiVersion: kubeadm.k8s.io/v1beta2
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 2001:250:4000:2000::53
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
kubeletExtraArgs:
node-ip: "2001:250:4000:2000::53"
#---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "[2001:250:4000:2000::53]:6443"
dns:
type: CoreDNS
imageRepository: k8s.gcr.io
controllerManager:
extraArgs:
#feature-gates: IPv6DualStack=true
bind-address: "::"
service-cluster-ip-range: fd03::/120
cluster-cidr: "fd04::/120"
kind: ClusterConfiguration
kubernetesVersion: v1.17.4
networking:
dnsDomain: cluster.local
serviceSubnet: "fd03::/120"
podSubnet: "fd04::/120"
#---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
failSwapOn: false
#---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
clusterCIDR: "fd03::/120"
mode: "ipvs"修改了calico.yaml执行脚本的参数如下:
!这是dual的,ipv6-only的把ipv4的部分去掉1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56kind: ConfigMap
...
data:
...
cni_network_config: |-
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
...
"ipam": {
"type": "calico-ipam",
"assign_ipv4": "true",
"assign_ipv6": "true",
"ipv4_pools": ["192.170.30.0/16", "default-ipv4-ippool"],
"ipv6_pools": ["fd03::/120", "default-ipv6-ippool"]
},
...
},
...
]
}
...
...
#---
kind: DaemonSet
...
spec:
...
template:
...
spec:
...
containers:
- name: calico-node
image: calico/node:v3.13.1
env:
...
- name: CALICO_IPV4POOL_CIDR
value: "192.170.30.0/16"
...
# Disable IPv6 on Kubernetes.
- name: FELIX_IPV6SUPPORT
value: "true"
...
- name: CALICO_IPV6POOL_CIDR
value: fd04::/120
- name: IP6
value: "autodetect"
# !注意,这是后来做outgress发现的,ipv6环境默认不会配网关,see
# https://docs.projectcalico.org/reference/node/configuration
# 所以这里要加个参数
- name: CALICO_IPV6POOL_NAT_OUTGOING
value: true
...create检查service地址能不能对上,具体debug步骤忘了,大概用了这些命令:
1
2ss -atnlp | grep 443
netstat -an|grep 6443
又装了个Nginx pod以后,试图写一个测试service看能不能通过Nginx ping通ipv6地址,失败
- service.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: Service
metadata:
name: cec
spec:
ipFamily: IPv6
ports:
- name: http
port: 8080
protocol: TCP
targetPort: 80
selector:
app: nginx - nginx.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19piVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80 - debug
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61root@192-168-1-61 ok8s]# kubectl apply -f service.yaml
service/cec created
[root@192-168-1-61 ok8s]# kubectl get service -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default cec ClusterIP fd03::7d <none> 8080/TCP 35s
default kubernetes ClusterIP fd03::1 <none> 443/TCP 4h36m
kube-system kube-dns ClusterIP fd03::a <none> 53/UDP,53/TCP,9153/TCP 4h36m
[root@192-168-1-61 ok8s]# kubectl describe -n default pod nginx-deployment-574b87c764-qptmz
...
Node: 192-168-1-61.maas/2001:250:4000:2000::53
Labels: app=nginx
Annotations: cni.projectcalico.org/podIP: fd04::d5/128
cni.projectcalico.org/podIPs: fd04::d5/128
IP: fd04::d5
Containers:
nginx:
Container ID: docker://199c74a7f44d431d95091d991025e43b24dca7fa9cc9d77e3781af1b89f160ce
Image: nginx:1.14.2
Port: 80/TCP
Host Port: 0/TCP
...
[root@192-168-1-61 ok8s]# kubectl get pods -o yaml | grep -i podip
cni.projectcalico.org/podIP: fd04::d5/128
cni.projectcalico.org/podIPs: fd04::d5/128
podIP: fd04::d5
podIPs:
[root@192-168-1-61 ok8s]# kubectl describe svc cec
...
Selector: app=nginx
Type: ClusterIP
IP: fd03::7d
Port: http 8080/TCP
TargetPort: 80/TCP
Endpoints: [fd04::d5]:80
[root@192-168-1-61 ok8s]# curl -vvv -k http://[fd03::7d]:8080 -g
* About to connect() to fd03::7d port 8080 (#0)
* Trying fd03::7d...
* Connection refused
* Failed connect to fd03::7d:8080; Connection refused
* Closing connection 0
curl: (7) Failed connect to fd03::7d:8080; Connection refused
[root@192-168-1-61 ok8s]# >/dev/tcp/fd03::7d/8080
-bash: connect: Connection refused
-bash: /dev/tcp/fd03::7d/8080: Connection refused
[root@192-168-1-61 ok8s]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP [fd03::1]:443 rr
-> [2001:250:4000:2000::53]:6443 Masq 1 4 0
TCP [fd03::a]:53 rr
-> [fd04::cf]:53 Masq 1 0 0
-> [fd04::d7]:53 Masq 1 0 0
TCP [fd03::a]:9153 rr
-> [fd04::cf]:9153 Masq 1 0 0
-> [fd04::d7]:9153 Masq 1 0 0
TCP [fd03::7d]:8080 rr
-> [fd04::d5]:80 Masq 1 0 0
UDP [fd03::a]:53 rr
-> [fd04::cf]:53 Masq 1 0 0
-> [fd04::d7]:53 Masq 1 0 01
2
3
4
5
6[root@192-168-1-61 cec-installer]# kubectl get svc,deploy
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP fd03::1 <none> 443/TCP 137m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 2/2 2 2 105m1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40[root@192-168-1-61 ok8s]# kubectl exec -it nginx-deployment-574b87c764-qptmz bash
root@nginx-deployment-574b87c764-qptmz:/# >/dev/tcp/127.0.0.1/80
root@nginx-deployment-574b87c764-qptmz:/# >/dev/tcp/fd04::d5/80
bash: connect: Connection refused
bash: /dev/tcp/fd04::d5/80: Connection refused
root@nginx-deployment-574b87c764-qptmz:/# cd /etc/nginx/
root@nginx-deployment-574b87c764-qptmz:/etc/nginx# cat nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
// not modified on my desktop, thus skip the modification here
root@nginx-deployment-574b87c764-qptmz:/etc/nginx# nginx -s reload
2020/03/26 09:01:37 [notice] 28#28: signal process started
root@nginx-deployment-574b87c764-qptmz:/etc/nginx# >/dev/tcp/fd04::d5/80
- service.yaml
install helm/tiller/nfs/ingress
Background: no connection to outer internet on host server, install helm and tiller locally, export tiller image and transfer it to host server.Step1: install helm
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23wget https://get.helm.sh/helm-v2.16.1-linux-amd64.tar.gz
// transfer package to host server:/var/tmp/xxx-installer/
[root@192-168-1-61 cec-installer]# tar zxvf helm-v2.16.1-linux-amd64.tar.gz
linux-amd64/
linux-amd64/helm
linux-amd64/LICENSE
linux-amd64/tiller
linux-amd64/README.md
[root@192-168-1-61 cec-installer]# sudo install **/helm /usr/bin
[root@192-168-1-61 cec-installer]# helm version
Client: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"}
Error: could not find tiller
[root@192-168-1-61 cec-installer]# helm init
Creating /root/.helm
Creating /root/.helm/repository
Creating /root/.helm/repository/cache
Creating /root/.helm/repository/local
Creating /root/.helm/plugins
Creating /root/.helm/starters
Creating /root/.helm/cache/archive
Creating /root/.helm/repository/repositories.yaml
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
Error: error initializing: Looks like "https://kubernetes-charts.storage.googleapis.com" is not a valid chart repository or cannot be reached:etes-charts.storage.googleapis.com/index.yaml: dial tcp: lookup kubernetes-charts.storage.googleapis.com on 10.136.40.87:53: server misbehavihere refered https://www.jianshu.com/p/2bb1dfdadee8
1
2
3
4
5// 这一步不知道要不要做,反正我先做了
[root@192-168-1-61 cec-installer]# cd linux-amd64/
[root@192-168-1-61 linux-amd64]# ls
LICENSE README.md helm tiller
[root@192-168-1-61 linux-amd64]# vim rbac-config.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system1
2
3[root@192-168-1-61 linux-amd64]# kubectl create -f rbac-config.yaml
serviceaccount/tiller created
clusterrolebinding.rbac.authorization.k8s.io/tiller createdStep2: init tiller
save localtillerimage and transfer it to host server, then follow the answer@Amit-Thawait这里还遇到一个问题,本地win10的helm和tiller以前装的是2.14,这次用了2.16,不知如何升级,问了一下,原来是用2.16的helm.exe和tiller.exe文件替换掉
/.helm/下的俩对应exe再init一遍就行了,估计linux上的更新就是替换一下二进制文件吧。。 1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@host63 cec-installer]# docker image tag 1f92aa902d73 gcr.io/kubernetes-helm/tiller:v2.16.1
[root@192-168-1-61 cec-installer]# helm init --client-only --skip-refresh
Creating /root/.helm/repository/repositories.yaml
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
Adding local repo with URL: http://127.0.0.1:8879/charts
$HELM_HOME has been configured at /root/.helm.
Not installing Tiller due to 'client-only' flag having been set
// load tiller image
[root@192-168-1-61 cec-installer]# helm init
$HELM_HOME has been configured at /root/.helm.
Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
To prevent this, run `helm init` with the --tiller-tls-verify flag.
For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installationhelm error happens:
1
2
3
4[root@192-168-1-61 cec-installer]# helm version
Client: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"}
E0326 23:21:17.649683 11541 portforward.go:400] an error occurred forwarding 39127 -> 44134: error forwarding port 44134 to pod 8d197e975824256d2de574f4577161702560b55a4aa70978bac91f2e43abe712, uid : unable to do port forwarding: socat not found
E0326 23:21:18.652732 11541 portforward.go:400] an error occurred forwarding 39127 -> 44134: error forwarding port 44134 to pod 8d197e975824256d2de574f4577161702560b55a4aa70978bac91f2e43abe712, uid : unable to do port forwarding: socat not foundAccording to https://www.kubernetes.org.cn/3879.html, this error happens due to rr is not set to permitted in k8s net config, install socat to fix it. (internal yum repository has build up, thus download directly)
1
2
3
4[root@192-168-1-61 cec-installer]# yum install socat.x86_64
[root@192-168-1-61 cec-installer]# helm version
Client: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.16.4", GitCommit:"5e135cc465d4231d9bfe2c5a43fd2978ef527e83", GitTreeState:"clean"}版本好像没对上,懒得重装了凑合用吧。
Step3: install nfs
[error] cannot install nfs:1
2helm install stable/nfs-server-provisioner --name nfs-provisioner --set persistence.storageClass=nfs --set persistence.size=20Gi --set rbac.create=true
Error: validation failed: [storageclasses.storage.k8s.io "nfs" not found, serviceaccounts "nfs-provisioner-nfs-server-provisioner" not found, clusterroles.rbac.authorization.k8s.io "nfs-provisioner-nfs-server-provisioner" not found, clusterrolebindings.rbac.authorization.k8s.io "nfs-provisioner-nfs-server-provisioner" not found, services "nfs-provisioner-nfs-server-provisioner" not found, statefulsets.apps "nfs-provisioner-nfs-server-provisioner" not found]try to downgrade tiller to 2.16.1 on windows:
1
2$ helm reset --force
$ helm init -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.16.1nfs installed on windows successfully:
1
2
3
4$ kubectl get storageclass
NAME PROVISIONER AGE
hostpath (default) docker.io/hostpath 7d3h
nfs cluster.local/nfs-provisioner-nfs-server-provisioner 102sfor offline linux server, firstly download helm chart package, then package the chart files to tgz, helm install it on host server:
1
2
3
4
5[root@192-168-1-61 cec-installer]# helm install -n nfs-provisioner ./nfs-servier-provisoner.tgz \
> --set persistence.storageClass=nfs \
> --set persistence.size=20Gi
Error: release nfs-provisioner failed: namespaces "default" is forbidden: User "system:serviceaccount:kube-system:default" cannot get resource "namespaces" in API group "" in the namespace "default"应该是helm创建sa时未添加helm-tiller,按这个步骤加上就ok了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19[root@192-168-1-61 cec-installer]# kubectl create serviceaccount --namespace kube-system helm-tiller
serviceaccount/helm-tiller created
[root@192-168-1-61 cec-installer]# kubectl create clusterrolebinding helm-tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:helm-tiller
clusterrolebinding.rbac.authorization.k8s.io/helm-tiller-cluster-rule created
[root@192-168-1-61 cec-installer]# helm init --service-account=helm-tiller --upgrade
$HELM_HOME has been configured at /root/.helm.
Tiller (the Helm server-side component) has been updated to gcr.io/kubernetes-helm/tiller:v2.16.1 .
[root@192-168-1-61 cec-installer]# helm install -n nfs-provisioner ./nfs-servier-provisoner.tgz --set persistence.storageClass=nfs --set persistence.size=20Gi
NAME: nfs-provisioner
LAST DEPLOYED: Mon Mar 30 02:13:19 2020
NAMESPACE: default
STATUS: DEPLOYED
...
[root@192-168-1-61 cec-installer]# kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs cluster.local/nfs-provisioner-nfs-server-provisioner Delete Immediate true 2m42sStep4: install nginx-ingress, similar to installing nfs
1
2
3docker load -i ingress-nginx.tar.gz
docker image tag 20c7790fd73d quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.29.0
helm install -n nginx-ingress ./nginx-ingress-deploy.tgz --set rbac.create=true
finally, start to install our product
产品jenkins-ci因为没人维护挂了。。只好本地打包
step1:
./startindesignenv.sh -c -d-d步骤中最后为npm start所以最后不会停要手动cancel进程。build + deploy完了以后可以在coreservice/backend/webroot(类似target)下找到拷贝过去的前端编译文件。step2: 在任一service目录下(例:coreservice)
$ docker build -t <package-name> .执行打包,coreservice比较特殊,因为前后端一体所以要执行第一步先把前端整合到后端,其他service直接打包即可。error1:
1
2Step 1/15 : FROM node:10.15.3-alpine
error pulling image configuration: Get https://registry-1.docker.io/v2/library/node/blobs.. net/http: TLS handshake timeoutsolution : network not stable, ignore and build again
error2:
1
2
3
4
5
6
7
8
9Step 2/15 : RUN apk add --no-cache bash openssl
fetch http://dl-cdn.alpinelinux.org/alpine/v3.9/main/x86_64/APKINDEX.tar.gz
WARNING: Ignoring http://dl-cdn.alpinelinux.org/alpine/v3.9/main/x86_64/APKINDEX.tar.gz: network error (check Internet connection and firewall)
ERROR: unsatisfiable constraints:
bash (missing):
required by: world[bash]
openssl (missing):
required by: world[openssl]
The command '/bin/sh -c apk add --no-cache bash openssl' returned a non-zero code: 2solution: didnt figure out the detailed reason, but restart docker cannot solve this issue. Thanks to Ye who taught me to add
1
2ENV HTTP_PROXY="http://www-proxy.lmera.ericsson.se:8080"
ENV HTTPS_PROXY="http://www-proxy.lmera.ericsson.se:8080"to Dockerfile, the problem due to no connection to external link while running the
alpinelinux.the proxy ENV config will also take effect on container running on host server after loading, we would better use
--build-argwhen executedocker build, see https://www.cntofu.com/book/139/image/dockerfile/arg.md
e.g. $ docker build -t core-cec . –build-arg HTTP_PROXY=”http://www-proxy.lmera.ericsson.se:8080"
Step3: install on linux server
docker load -i <package>helm install -n eri2 ./cec-release-1.0.0.tgz --set service.type=NodePort --set persistence.enabled=false --set persistence.storageClass=nfs --set persistence.database.size=5Gi --set persistence.miscellaneous.size=5Gi- deployed but got error, when building one service container, run image as container and enter to check:it may due to the some nodes in
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25[root@192-168-1-61 cec-installer]# docker run -it registry/cec-sai:1.0.0 sh
/opt/ericsson/cec/saiservice # /usr/local/bin/npm start
/opt/ericsson/cec/saiservice/node_modules/bindings/bindings.js:91
throw e
^
Error: Error loading shared library /opt/ericsson/cec/saiservice/node_modules/libxmljs/build/Release/xmljs.node: Exec format error
at Object.Module._extensions..node (internal/modules/cjs/loader.js:730:18)
at Module.load (internal/modules/cjs/loader.js:600:32)
at tryModuleLoad (internal/modules/cjs/loader.js:539:12)
at Function.Module._load (internal/modules/cjs/loader.js:531:3)
at Module.require (internal/modules/cjs/loader.js:637:17)
at require (internal/modules/cjs/helpers.js:22:18)
at bindings (/opt/ericsson/cec/saiservice/node_modules/bindings/bindings.js:84:48)
at Object.<anonymous> (/opt/ericsson/cec/saiservice/node_modules/libxmljs/lib/bindings.js:1:99)
at Module._compile (internal/modules/cjs/loader.js:701:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:712:10)
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! CEC_SAI_Handler@1.0.0 start: `node server.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the CEC_SAI_Handler@1.0.0 start script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2020-03-31T02_30_46_424Z-debug.lognpm_modulesnot work both on windows and linux env. ref: https://dzone.com/articles/packaging-a-node-app-for-docker-from-windows
solution: removenode_modulesbefore docker image build, npm install all packages in docker container, thus it will be generated in linux format.build and check image:1
2
3
4
5...
COPY . ./
RUN rm -rf node_modules
...
npm installsave image:1
2
3
4
5
6
7
8
9
10$ docker build -t cec-sai . --build-arg HTTP_PROXY="http://www-proxy.lmera.ericsson.se:8080"
$ winpty docker run -it cec-sai sh
/opt/ericsson/cec/saiservice # find / -name npm
/usr/local/lib/node_modules/npm
/usr/local/lib/node_modules/npm/bin/npm
/usr/local/bin/npm
/opt/ericsson/cec/saiservice # /usr/local/bin/npm start
> CEC_SAI_Handler@1.0.0 start /opt/ericsson/cec/saiservice
> node server.js
sequelize deprecated String based operators are now deprecated. Please use Symbol based operators for better security, read more at http://docs.sequelizejs.com/manual/tutorial/querying.html#operators node_modules/sequelize/lib/sequelize.js:245:13then load it to host server on linux1
$ docker save -o cec-sai-200327.tar.gz cec-sai
Run enm server via docker container is a simpler way, use
docker run -itd --name <simulator-name> -p 8091:8091 -v <volume-path> <image-id or name>, volune path can be skipped to set, remind to expose port 8091 or the container cannot be accessed. (port depends on your design)
Step4: install simulator
save image on windows, load it to linux, then start simulator service on linux server:1
2$ kubectl create deployment xxx-simulator --image=xxx-simulator:1.0.0
deployment.apps/xxx-simulator createdget simulator ip address:
1
2
3$ kubectl get pod -l app=enm-simulator -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
xxx-simulator-79d68f588f-8l2fq 1/1 Running 0 4m3s fd04::fb 192-168-1-61.maas <none> <none>
Test functionalities
[error1] connot apply ipv6 address in our settings.
solution: change validation regex from^http(s)?://[\\w\\.\\-?=%&:/]+$to^http(s)?://([\[\\w\\.\\-?=%&:/](\])?)+$[error2] cannot connect to simulator when do cell import:
solution: modify defaultHOSTconfig inserver.jsfrom ‘0.0.0.0’ to ‘’. see official node.js docs section = server.listen(options[, callback])
here I record my debug history:1
2
3
4
5
6[root@192-168-1-61 ~]# kubectl exec -it xxx-simulator-79d68f588f-8l2fq bash
bash-4.4# netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8091 0.0.0.0:* LISTEN 23/node
tcp 0 0 0.0.0.0:8092 0.0.0.0:* LISTEN 23/nodethe ip is deafult in ipv4 format, so enter our core service (frontend and backend) pod to check more.
1
2
3
4
5
6[root@192-168-1-61 ~]# kubectl exec -it -c xxx-core eri1-xxx-6c4b88cd75-7plb8 bash
bash-4.4# ping6 fd04::fd
PING fd04::fd (fd04::fd): 56 data bytes
64 bytes from fd04::fd: seq=0 ttl=63 time=0.144 ms
64 bytes from fd04::fd: seq=1 ttl=63 time=0.179 ms
64 bytes from fd04::fd: seq=2 ttl=63 time=0.069 msfd04::fd is the ipv6 address of simulator, so simulator can be accessed by core service.
1
2
3
4
5
6
7
8
9
10
11bash-4.4# netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN -
tcp 0 0 :::8082 :::* LISTEN -
tcp 0 0 :::8083 :::* LISTEN -
tcp 0 0 :::8084 :::* LISTEN -
tcp 0 0 :::8888 :::* LISTEN 16/node
tcp 0 0 :::5432 :::* LISTEN -
tcp 0 0 :::8443 :::* LISTEN 16/node
tcp 0 0 :::8585 :::* LISTEN 16/nodeports are all correct, so there might be errors in simulator codes
1
2
3
4
5
6
7[root@192-168-1-61 ~]# kubectl exec -it enm-simulator-77c8886b88-7ksxk bash
bash-4.4# grep -i host /opt/eri../xxx/simulatorservice/server.js
const HOST = '0.0.0.0';
httpServer.listen(HTTP_PORT, HOST, () => {
LOGGER.info("HTTP Server is running on : http://%s:%s", HOST, HTTP_PORT);
httpsServer.listen(HTTPS_PORT, HOST, () => {
...果然。。。config default HOST = ‘0.0.0.0’ –> HOST = ‘’
system error :
connect ECONNREFUSED 127.0.0.1:8091,ENM=http://[fd04::fe]:8091
this error indicate the default route the simulator service connect to is not correct, check in codes I found:1
2
3
4
5
6
7
8
9
10
11
12
13module.exports = {
ENMSERVICEPROTOCO: process.env.enmserviceprotoco || 'http:',
ENMSERVICEPORT: process.env.enmserviceport || 8083,
ENMSERVICEHOST: process.env.enmservicehost || '',
ENMNODEPROTOCO: process.env.enmnodeprotocol || 'http:',
ENMNODEPORT: process.env.enmnodeport || 8091,
ENMNODEHOST: process.env.enmnodehost || 'localhost',
CORENODEPROTOCO: process.env.corenodeprotocol || 'http:',
CORENODEPORT: process.env.corenodeport || 8585,
CORENODEHOST: process.env.corenodehost || 'localhost',
}I guess there should be a
ENVparameter configured in xxx simulator deployment.yaml. To temporarily fix this problem, I edit the deployment config of xxx-simulator, refer answer and k8s official doc:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15...
spec:
...
template:
metadata:
creationTimestamp: null
labels:
app: xxx-simulator
spec:
containers:
- env:
- name: enmnodehost
value: '[fd04::fe]'
image: xxx-simulator:1.0.0
...这方法不对,原因:
connect ECONNREFUSED 127.0.0.1:8091是enmservice和simulator在通信,这个相当于连了localhost:8091 (查看enmservice的log也确实如此),理论上应连[fd04::fe]:8091。问题出在enmservice request export of simulator的地址,所以改simulator的container启动配置没用。
检查simulator的export代码,发现当时写的时候没考虑到ipv6,因为我们的create完job以后从simulator export的jobUrl是这么传的。。1
2const fqdn = req.headers && req.headers["host"] ? req.headers["host"].split(':')[0] : null;
JOBSDATA = new JOBS(moJobId, fqdn);所以error message里会出现
http://[fd04:8091/bulk-con...这种url1
2
3
4
5
6
7
8
9
10"message": "Error: connect ECONNREFUSED ::1:8091",
"options": {
"ca": [
""
],
"jar": {},
"url": "http://[fd04:8091/bulk-configuration/v1/import-jobs/jobs/18974277/files",
"method": "POST"
...
}改了一下
1
2
3
4
5
6
7
8
9
10
11
12
13var fqdn = "";
if (req.headers && req.headers["host"]) {
const headerHost = req.headers["host"];
if (/\[/.test(headerHost)) {
let start = headerHost.indexOf('[');
let end = headerHost.indexOf(']');
fqdn = headerHost.slice(start, end + 1);
} else {
fqdn = headerHost.split(':')[0];
}
} else {
fqdn = null;
}